
CPU/GPU/TPU Performance Comparison
Published:
I have implemented a simple comparison of performance on Google Colab CPU, GPU, and TPU as part of an assignment for COSC 6385 course at the University of Houston.
A sample implementation can be found in the following repository.
I followed the basic step-by-step guide in 1. I also followed the instructions to work on TPU using 2.
First, we need to import the following libraries, set the configuration to log the information, and filter out the warnings.
- tensorflow - for computations with matrices.
- timeit - to compute the time taken
import tensorflow as tf
import timeit
import warnings
warnings.filterwarnings('ignore')
tf.get_logger().setLevel('INFO')
SIMPLE IMPLEMENTATION
CPU-Version
The code below shows the version of code that can be executed on the CPU
cpu = tf.config.experimental.list_physical_devices('CPU')[0]
print(f'Selected CPU: {cpu}')
testcpu = """
import tensorflow as tf
with tf.device('/cpu:0'):
random_image_cpu = tf.random.normal((100, 100, 100, 3))
net_cpu = tf.compat.v1.layers.conv2d(random_image_cpu, 32, 7)
net_cpu = tf.math.reduce_sum(net_cpu)
"""
cpu_time = timeit.timeit(testcpu, number=10)
print('Time (s) to convolve 32x7x7x3 filter over random 100x100x100x3 images \n'
f'(batch x height x width x channel). Sum of ten runs: {cpu_time}')
While running on google colab in CPU mode make sure the following configuration
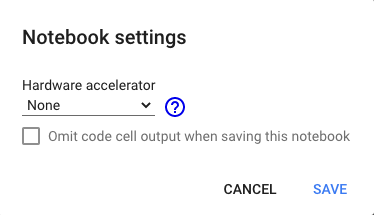
And you can obtain the following outputs
Selected CPU: PhysicalDevice(name='/physical_device:CPU:0', device_type='CPU')
Time (s) to convolve 32x7x7x3 filter over random 100x100x100x3 images
(batch x height x width x channel). Sum of ten runs: 3.8407666499999777
GPU-Version
The code below shows the version of code that can be executed on the GPU
gpu = tf.config.experimental.list_physical_devices('GPU')[0]
print(f'Selected GPU: {gpu}')
testgpu = """
import tensorflow as tf
with tf.device('/device:GPU:0'):
random_image_gpu = tf.random.normal((100, 100, 100, 3))
net_gpu = tf.compat.v1.layers.conv2d(random_image_gpu, 32, 7)
net_gpu = tf.math.reduce_sum(net_gpu)
"""
gpu_time = timeit.timeit(testgpu, number=10)
print('Time (s) to convolve 32x7x7x3 filter over random 100x100x100x3 images \n'
f'(batch x height x width x channel). Sum of ten runs. {gpu_time}')
print(f'GPU speedup over CPU: {int(cpu_time/gpu_time)}x')
While running on google colab in GPU mode make sure the following configuration.
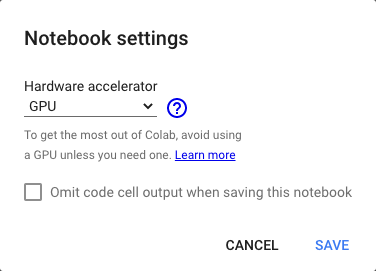
And you can obtain the following outputs
Selected GPU: PhysicalDevice(name='/physical_device:GPU:0', device_type='GPU')
Time (s) to convolve 32x7x7x3 filter over random 100x100x100x3 images
(batch x height x width x channel). Sum of ten runs. 0.056331392000004143
GPU speedup over CPU: 51x
TPU-Version
I was able to run the CPU version as well as the GPU version, but the TPU version does not work. The following code shows the initial TPU version of code that does not work, as mentioned in the tutorial,
tpu = tf.config.experimental.list_physical_devices('XLA_CPU')[0]
print(f'Selected TPU: {tpu}')
testtpu = """
import tensorflow as tf
with tf.device('/device:XLA_CPU:0'):
random_image_tpu = tf.random.normal((100, 100, 100, 3))
net_tpu = tf.compat.v1.layers.conv2d(random_image_tpu, 32, 7)
net_tpu = tf.math.reduce_sum(net_tpu)
"""
tpu_time = timeit.timeit(testtpu, number=10)
print('Time (s) to convolve 32x7x7x3 filter over random 100x100x100x3 images \n'
f'(batch x height x width x channel). Sum of ten runs. {tpu_time}')
print(f'TPU speedup over CPU: {int(cpu_time/tpu_time)}x')
And obtain the following error message
---------------------------------------------------------------------------
IndexError Traceback (most recent call last)
<ipython-input-3-77bc147ae849> in <module>()
----> 1 tpu = tf.config.experimental.list_physical_devices('XLA_CPU')[0]
2 print(f'Selected TPU: {tpu}')
3
4 testtpu = """
5 import tensorflow as tf
IndexError: list index out of range
To solve the TPU version, I go through the solution provided in the 2, 3 and fixed the issues. Finally, the code below shows the version of code that can be executed on the TPU.
try:
tpu = tf.distribute.cluster_resolver.TPUClusterResolver()
print('Running on TPU ', tpu.cluster_spec().as_dict()['worker'])
except ValueError:
raise BaseException('ERROR: Not connected to a TPU runtime; '
'please see the previous cell in this notebook for instructions!')
testtpu = """
import tensorflow as tf
with tf.device('/device:XLA_CPU:0'):
random_image_tpu = tf.random.normal((100, 100, 100, 3))
net_tpu = tf.compat.v1.layers.conv2d(random_image_tpu, 32, 7)
net_tpu = tf.math.reduce_sum(net_tpu)
"""
tpu_time = timeit.timeit(testtpu, number=10)
print('Time (s) to convolve 32x7x7x3 filter over random 100x100x100x3 images '
f'(batch x height x width x channel). Sum of ten runs. {tpu_time}')
print(f'TPU speedup over CPU: {int(cpu_time/tpu_time)}x')
While running on google colab in TPU mode make sure the following configuration is set as shown in the following image,
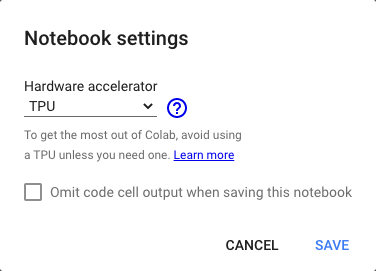
And you can obtain the following outputs
Running on TPU ['10.61.126.18:8470']
Time (s) to convolve 32x7x7x3 filter over random 100x100x100x3 images (batch x height x width x channel). Sum of ten runs. 3.5220498910000515
TPU speedup over CPU: 1x
Summary:
Based on the results, the CPU and TPU perform nearly the same, but the GPU performs more than 50 times faster than the CPU and TPU
A Basic Convolutional Neural Network (CNN) Implementation
The code below shows a sample CNN network implementation.
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.fashion_mnist.load_data()
x_train = np.expand_dims(x_train, -1)
x_test = np.expand_dims(x_test, -1)
sss = StratifiedShuffleSplit(n_splits=5, random_state=0, test_size=1 / 6)
train_index, valid_index = next(sss.split(x_train, y_train))
x_valid, y_valid = x_train[valid_index], y_train[valid_index]
x_train, y_train = x_train[train_index], y_train[train_index]
model = tf.keras.models.Sequential()
model.add(tf.keras.layers.BatchNormalization(input_shape=x_train.shape[1:]))
model.add(tf.keras.layers.Conv2D(64, (5, 5), padding='same', activation='elu'))
model.add(tf.keras.layers.MaxPooling2D(pool_size=(2, 2), strides=(2, 2)))
model.add(tf.keras.layers.Dropout(0.25))
model.add(tf.keras.layers.BatchNormalization(input_shape=x_train.shape[1:]))
model.add(tf.keras.layers.Conv2D(128, (5, 5), padding='same', activation='elu'))
model.add(tf.keras.layers.MaxPooling2D(pool_size=(2, 2)))
model.add(tf.keras.layers.Dropout(0.25))
model.add(tf.keras.layers.BatchNormalization(input_shape=x_train.shape[1:]))
model.add(tf.keras.layers.Conv2D(256, (5, 5), padding='same', activation='elu'))
model.add(tf.keras.layers.MaxPooling2D(pool_size=(2, 2), strides=(2, 2)))
model.add(tf.keras.layers.Dropout(0.25))
model.add(tf.keras.layers.Flatten())
model.add(tf.keras.layers.Dense(256))
model.add(tf.keras.layers.Activation('elu'))
model.add(tf.keras.layers.Dropout(0.5))
model.add(tf.keras.layers.Dense(10))
model.add(tf.keras.layers.Activation('softmax'))
model.summary()
model.compile(
optimizer=tf.optimizers.Adam(learning_rate=1e-3, ),
loss=tf.keras.losses.sparse_categorical_crossentropy,
metrics=['sparse_categorical_accuracy']
)
The code below shows the version of code that can be executed on the GPU
import tensorflow as tf
import timeit
import warnings
warnings.filterwarnings('ignore')
tf.get_logger().setLevel('INFO')
gpus = tf.config.experimental.list_physical_devices('GPU')[0]
print(f'Selected GPU: {gpu}')
tf.config.experimental.set_memory_growth(gpu, True)
testgpu = """
import os
import tensorflow as tf
import numpy as np
import pandas as pd
from sklearn.model_selection import StratifiedShuffleSplit
with tf.device('/device:GPU:0'):
<SAMPLE CNN CODE>
"""
gpu_time = timeit.timeit(testgpu, number=10)
print('GPU time taken (seconds):', gpu_time)
Same as previous section, while running on google colab in GPU mode make sure the following configuration is set as shown already. And you can obtain the following outputs
PhysicalDevice(name='/physical_device:GPU:0', device_type='GPU')
GPU (s):
PhysicalDevice(name='/physical_device:GPU:0', device_type='GPU')
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/train-labels-idx1-ubyte.gz
32768/29515 [=================================] - 0s 0us/step
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/train-images-idx3-ubyte.gz
26427392/26421880 [==============================] - 0s 0us/step
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/t10k-labels-idx1-ubyte.gz
8192/5148 [===============================================] - 0s 0us/step
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/t10k-images-idx3-ubyte.gz
4423680/4422102 [==============================] - 0s 0us/step
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
batch_normalization (BatchNo (None, 28, 28, 1) 4
_________________________________________________________________
conv2d (Conv2D) (None, 28, 28, 64) 1664
_________________________________________________________________
.....
.....
.....
dense_18 (Dense) (None, 256) 590080
_________________________________________________________________
activation_18 (Activation) (None, 256) 0
_________________________________________________________________
dropout_39 (Dropout) (None, 256) 0
_________________________________________________________________
dense_19 (Dense) (None, 10) 2570
_________________________________________________________________
activation_19 (Activation) (None, 10) 0
=================================================================
Total params: 1,619,470
Trainable params: 1,619,084
Non-trainable params: 386
_________________________________________________________________
10.992455269000004
GPU time taken (seconds): 10.992455269000004
The code below shows the version of code that can be executed on the TPU
import tensorflow as tf
import timeit
import warnings
warnings.filterwarnings('ignore')
tf.get_logger().setLevel('INFO')
try:
tpu = tf.distribute.cluster_resolver.TPUClusterResolver()
print('Running on TPU ', tpu.cluster_spec().as_dict()['worker'])
except ValueError:
raise BaseException('ERROR: Not connected to a TPU runtime; please see the previous cell in this notebook for instructions!')
testtpu = """
import os
import tensorflow as tf
import numpy as np
import pandas as pd
from sklearn.model_selection import StratifiedShuffleSplit
with tf.device('/device:XLA_CPU:0'):
<SAMPLE CNN CODE>
"""
tpu_time = timeit.timeit(testtpu, number=10)
print('TPU time taken (seconds):', tpu_time)
Again, same as the previous section, while running on Google Colab in TPU mode make sure the following configuration as before. And you can obtain the following outputs
Running on TPU ['10.18.116.242:8470']
TPU (s):
<tensorflow.python.distribute.cluster_resolver.tpu.tpu_cluster_resolver.TPUClusterResolver object at 0x7f825f37b690>
Model: "sequential_23"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
batch_normalization_69 (Batc (None, 28, 28, 1) 4
_________________________________________________________________
conv2d_69 (Conv2D) (None, 28, 28, 64) 1664
.....
.....
.....
_________________________________________________________________
activation_64 (Activation) (None, 256) 0
_________________________________________________________________
dropout_131 (Dropout) (None, 256) 0
_________________________________________________________________
dense_65 (Dense) (None, 10) 2570
_________________________________________________________________
activation_65 (Activation) (None, 10) 0
=================================================================
Total params: 1,619,470
Trainable params: 1,619,084
Non-trainable params: 386
_________________________________________________________________
TPU time taken (seconds): 6.602945475999945
Summary:
Based on the results, the TPU performs around 1.5 times better than the GPU in terms of the computation time for the CNN sample code.