
Emergency Responder Stationing
Published:
Recommended citation: Sivagnanam, A., Pettet, A., Lee, H., Mukhopadhyay, A., Dubey, A., & Laszka, A. (2024). Multi-Agent Reinforcement Learning with Hierarchical Coordination for Emergency Responder Stationing. In Proceedings of the 41 st International Conference on Machine Learning, (ICML 2024)
📌 Key Contributions
- Developed a novel Multi-Agent Deep Reinforcement Learning (DDPG) framework with hierarchical coordination to address the emergency responder stationing problem
- In the hierarchical setup, DDPG agents manage city-scale redistribution (high-level) and region-scale reallocation (low-level)
- Utilized a Transformer-based actor network to handle variable numbers of responders in region-scale reallocation
- Ensured feasible and exact mapping from continuous to discrete actions using min-cost flow (city-level) and max-weight matching (region-level), while preserving gradient flow during training
- Integrated low-level critics to provide reward feedback to high-level agents, enhancing training stability and performance
- Achieved 1000× faster decision-making and reduced response delays by 5–13 seconds on real-world datasets from Nashville and Seattle
🔍 High-Level Overview of the SOTA Approach with Hierarchical Coordination

This diagram illustrates our state-of-the-art hierarchical coordination framework that combines queuing-based city-scale redistributions and MCTS-based region-level reallocations of responders.
🧠 Region-Level Reallocation via DDPG Training
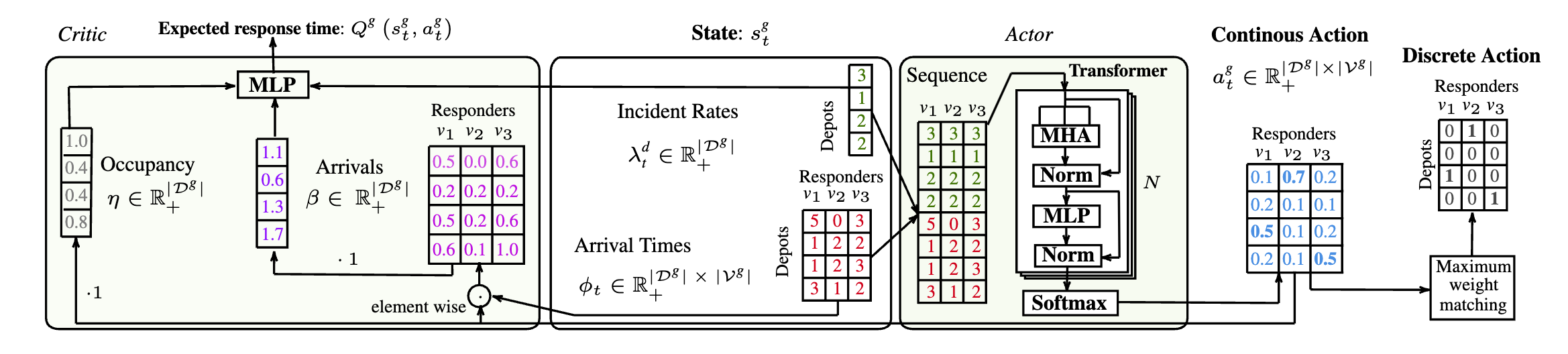
Leveraged DDPG to train agents that perform region-level reallocation of responders, enabling efficient adaptation to changing demand at a broader geographic scale.
🏙️ City-Level Redistribution via DDPG Training
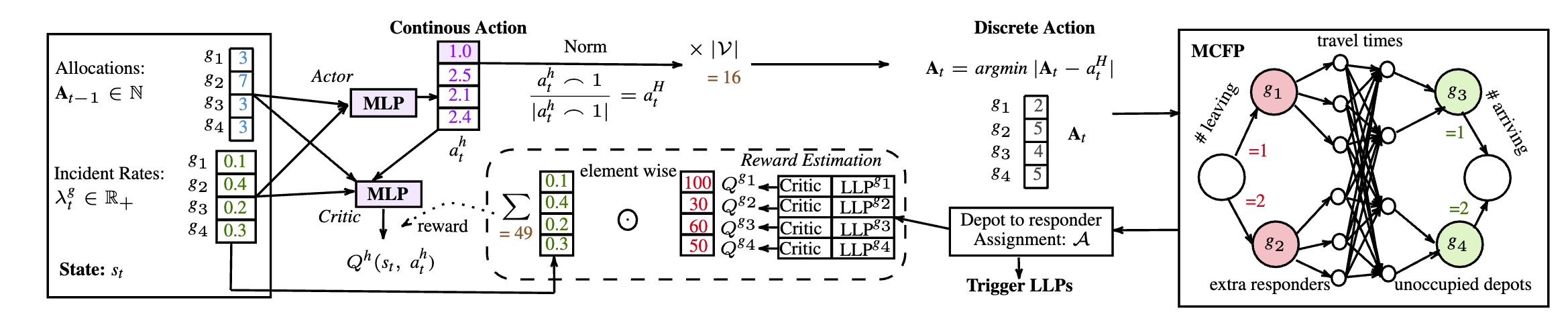
At the city scale, DDPG is used to train agents for fine-grained redistribution of responders, allowing precise real-time response in dense urban environments.
📝 Publication
Published as a full paper at ICML 2024 — “Multi-Agent Reinforcement Learning with Hierarchical Coordination for Emergency Responder Stationing.” [OpenReview]
💻 Code & Data
Reproducible code, training scripts, and Nashville & Seattle datasets: [Code & Data]
🎥 3-Minute Overview
Summarizing the challenges, solution approach, and results: [Short Video]